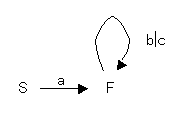
yylex()の中身は、有限状態オートマトンである。yylex()は文字を一文字づつ読みながら、正規表現に対応する状態遷移図に従って状態遷移していき、token を認識していく。
例えば、正規表現 a(b|c)* は次のような状態遷移図に対応する。 S が開始状態で、Fが終了状態である。 S から始めて全ての入力文字列を読み込み終えたときに、状態 F になっていれば、入力文字列は正規表現 a(b|c)* と一致するといえる。 途中で遷移不能な入力 (例えば状態 S のときに a 以外の入力) が来て状態 F に達しない場合、入力文字列は正規表現 a(b|c)* と一致しないことがわかる。
Lex の主要な仕事は、与えられた正規表現から状態遷移図を求めることである。 これについては、任意の正規表現から状態遷移図を求めるアルゴリズムがある。
まず正規表現を定義する。Alphabet A 上の正規表現とは、
正規表現は次のような規則で、非決定性オートマトンに変換できる。非決定性オートマトンとは、次にくる文字にかかわらず非決定的に遷移してもしなくてもよい、という矢印をもつオートマトンである。(下の図でラベルのついていない矢印が、非決定的な遷移をあらわす。)
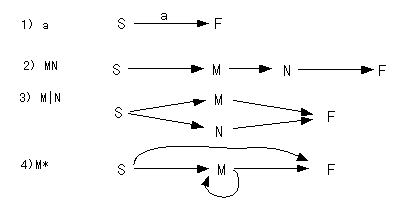
この規則にしたがって、a(b|c)* を非決定性オートマトンに変換すると次のようになる。

非決定的な遷移をもつオートマトンを実装すると非常に実行効率が悪い。非決定的な遷移はしてもしなくてもよい遷移なので、遷移した場合としない場合とを並列に調べるか、まず一方を調べ、失敗したら他方を調べるようしなければならない。
そこで、非決定的な遷移を取り除き、決定性オートマトンに変換する。基本的なアイデアは次のよう。
int i = 0;
while((c = getchar()) != EOF)
if(('A' <= c && c <= 'Z') || ('a' <= c && c <= 'z')){
do{
yytext[i++] = c;
c = getchar();
}while(('A' <= c && c <= 'Z') || ('a' <= c && c <= 'z'));
yytext[i] = '\0';
ungetc(c, stdin);
return IDENTIFIER;
}
getchar() で一文字づつ読みならが、状態遷移図にしたがって遷移できる間は、読んだ文字を
yytext[] に保存していく。そして、遷移できない文字に当たったら、そこで読みこみを止め、それまでに得た文字列を
token として返せばよい。最後に読んだ文字は、別の token の先頭であるかもしれないので、ungetc()
を使って元に戻すのが大切である。次に getchar() を呼んだとき、この文字はもう一度読みなおされる。
Lisp の場合、文法が単純で、プログラムの構造は括弧で明示的に示される。 そこで、要は yylex() が返してくる token 列から、開き括弧と閉じ括弧の対応を調べて、次のような木構造(リスト構造)を作ればよい。
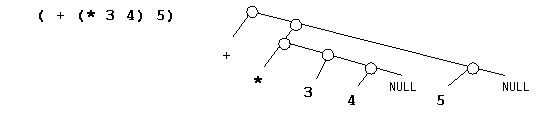
リスト構造とは、右側の枝が必ず木か NULL であるような、特殊な2分木である。 例えば (a) というプログラムは、左側の枝に a、右側の枝に NULL を持つ2分木で表される。 (a b) という式は、左側の枝に a、右側の枝に (b) を表す木を持つような、2分木で表される。 ((a) b c) という式は、左側の枝に (a)、右側の枝に (b c) を表す木を持つような、2分木で表される。 木の左側の枝には、必ず + や 5 などの要素が来るのがポイントである。 (* 3 4) のような括弧でくくられた式は、それ全体で1個の要素とみなされる。
上の図の中の○は、木のノードである。ノードの定義は(lisp.h)次のようになる。
struct _list {
enum { NAME, LIST, INTEGER } kind;
union {
char *symbol;
struct _list *list;
int integer;
} element;
struct _list *next;
};
typedef struct _list List;
左側の枝は、木構造の場合も、数やシンボルの場合もあるので、union になっている。また
union の中のデータの種類を区別するために enum 型の要素 kind をいれてある。enum
型を使わずに下のように書いても同じことである。enum 型を使うと、各定数を#define
で定義する手間をはぶける。
#define NAME 1
#define LIST 2
#define INTEGER 3
struct _list {
int kind;
union {
char *symbol;
struct _list *list;
int integer;
} element;
struct _list *next;
};
typedef struct _list List;
List 型のデータ構造を操作するための関数群を lisp.c
として用意した。
yytext[] の内容は新しい token を読むたびに書き変わってしまうので、AddSymbol()
を呼ぶときには yytext[] を別な配列にコピーしてから、渡す必要がある。このために、MakeSymbol()
という関数を lisp.c の中に用意した。
yylex.c を参考にすること。token の識別番号は lisp.h で定義されている。
yylex.c をコンパイルするには次のようにする。
gcc -DTEST yylex.c今のところ yylex.c の yylex() は、左右の括弧と数字しか認識できない。シンボルも認識できるようにすればよい。
次にできあがった yylex() を使って、与えられた Lisp のプログラムを構文解析して木構造を返す関数 Read() を作成せよ。read.c, lisp.c を参考にすること。
read.c をコンパイルするには次のようにする。
gcc -DREAD read.c lisp.c yylex.cこのプログラムは実行するとリストをひとつ読みこみ、解析結果を表示する。
今のところ、Read() は数とシンボルを認識して、長いリストを作るだけである。括弧を認識して、入れ子になったリストを作るようにすればよい。(なお yylex() がシンボルを認識できないので、結局 Read() は数しか認識しない。)
% ./a.out (+ 3 (* x 1)) ( "+" 3 ( "*" "x" 1 ) ) %のようになればよい。
Copyright (C) 1999-2000 Shigeru Chiba
Email: chiba@is.tsukuba.ac.jp