通常のプログラムの実行では、プログラムの各行は逐次的に実行されていくが、プログラムの種類によっては、プログラムの異なる部分を同時並行的 (concurrently) に実行できると便利なことがある。 このような並行処理をおこなっているときには、区別のために、それぞれの逐次的な処理の流れのことをスレッド (thread) と呼ぶ。 例えば、ある瞬間にプログラム中の関数 f() と g() が並行して実行されているとすると、その瞬間にはスレッドがふたつあり、ひとつのスレッドは f() を実行し、もう一方のスレッドは g() を実行している、などという。
一般に、並行(concurrent)と並列(parallel)は異なった意味に使い分けられることが多い。 並列は、マルチプロセッサなどによって複数のスレッドが実際に同時に動作している状態を意味するが、並行は実際に同時に動作している状態だけでなく、 シングルプロセッサで擬似的に同時に動作している状態も意味する。
複数のスレッドを使ってプログラミングできると、例えば、複数のユーザからの入力を同時に待って、入力された文字列を逐次表示するようなチャット・プログラムの作成が容易になる。 ユーザの数分のスレッドを用意して、それぞれのスレッドが異なるユーザからの入力を待つようにすればよいからである。 もし複数のスレッドが使えないと、そのようなプログラムは GUI プログラミングで見られるようなイベント駆動型のプログラムにしなければならず、プログラムの全体構造が複雑になりがちである。
カーネルレベル・スレッドは、文字通り OS カーネルによって直接実装されるスレッドである。 この実装の利点は、マルチプロセッサ構成のマシンなどでは、異なるスレッドに異なるプロセッサを割り当てて、スレッドを並列に実行させられることである。 もうひとつの利点は、スレッドの切り替えを、全プロセスのスケジューリングと融合しておこなえるので、I/O 待ちなどを有効に活用してスレッドを切り替えられることである。 OS カーネルから見ると、スレッドは独立したメモリ空間などを持たない、簡易なプロセスであると見なせるので、プロセスとスレッドを一緒にスケジューリングすることは理にかなっている。
一方、ユーザレベル・スレッドは、ユーザ・プロセスの中でライブラリだけによって実装される。 OS カーネルから見ると、ユーザレベル・スレッドは全体でひとつのスレッドであると認識される。 スレッドの切り替えには OS カーネルは関与しない。 ユーザレベル・スレッドの利点は、OS カーネルの助けを必要としないので、スレッドの切り替えが比較的高速におこなえることにある。 一方で、OS カーネルから見ると全体でひとつのスレッドであるので、マルチプロセッサ構成の恩恵をうけられない、I/O 待ちなどを有効に活用してスレッドの切り替えをおこなうことが難しい、などの欠点がある。 I/O 待ちなどのわずかな空き時間を利用して、他のスレッドを実行しようとすると、OS との密接なやり取りが必要になり、結局、高速なスレッド切り替えという元々の利点が失われてしまう。
ひとつのスレッドを構成する主要な部品は、レジスタとスタック・フレームである。 プログラムの実行に必要な情報は、全てレジスタかスタック・フレームに格納される。 したがってスレッドの実装の中核は、スレッド切り替えの度に、現在のレジスタとスタック・フレームの内容を、適当なメモリ中に退避し、新しく動かすスレッド用の内容をレジスタとスタック・フレームに復帰する機能の実装である。
一般にレジスタの内容は、特別なハードウェアによる支援がない限り、実際にメモリ中に退避するより他ないが、スタック・フレームの内容の退避の仕方には工夫の余地がある。 簡単な方法は、各スレッドごとに異なるスタック領域を用意しておいて、スレッドの切り替えごとに、スタック領域全体を切り替えるというものである。 この方法では、スレッドごとに比較的大きなスタック領域を確保しなければならないという欠点があるが、スレッド切り替えの度にスタック・フレームを他のメモリ領域にコピーするよりはずっと高速である。
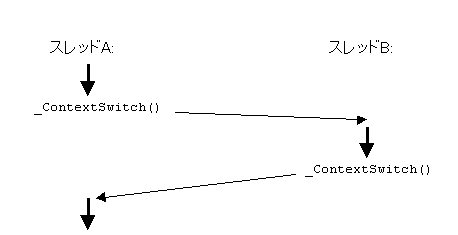
スレッド切り替えの機能は、レジスタの退避を伴うため、アセンブリ言語の使用が必要になる。 下に示すのは、x86 プロセッサ用にスレッド切り替えをおこなう関数 _ContextSwitch() である。
/*
void _ContextSwitch(int* old_context, int* new_context)
*/
.text
.align 2
.globl __ContextSwitch
__ContextSwitch:
movl 4(%esp),%edx
movl %ebx, 0(%edx)
movl %esp, 4(%edx)
movl %ebp, 8(%edx)
movl %esi, 12(%edx)
movl %edi, 16(%edx)
movl 8(%esp), %edx
movl 0(%edx), %ebx
movl 4(%edx), %esp
movl 8(%edx), %ebp
movl 12(%edx),%esi
movl 16(%edx),%edi
ret
引数 old_context, new_context はそれぞれ、大きさ 5 の int 配列へのポインタである。 この関数は、5 つのレジスタ ebx, esp, ebp, esi, edi を old_context が指す配列へ退避し、new_context が指す配列の内容を復帰させる。
この関数は、レジスタ esp (スタックポインタ) の値も交換するので、関数の実行後は、新しいスタック領域を使ってプログラムの実行が続けられるようになる。 最後の ret 命令は、スタックの頭から戻り番地を取り出すので、したがって、この関数を呼び出すと、戻り先は呼び出した関数ではなく、別なスレッドの関数である。 呼び出した関数に戻ってくるのは、別なスレッドの側で再び _ContextSwitch() を呼び出した後である。
_ContextSwitch() は、古いスレッド上の関数から呼び出されて、別なスレッド上の関数に戻る、あくまで関数であるので、全てのレジスタを退避・復帰させるわけではない。 例えばレジスタ edx や eax は退避も復帰もされない。 これは x86 の関数呼出し規約 (calling convention) により、レジスタ edx は関数の呼出側が退避することになっているからである。 またレジスタ eax には関数の返り値 (この場合は _ContextSwitch() の返り値) が入ることになっているので、同様に退避する必要はない。
/*
void _MakeThread(int* context, char* stack, void (*func)(int,int), int arg1, int arg2)
*/
.text
.align 2
.globl __MakeThread
__MakeThread:
movl 8(%esp),%edx /* stack */
movl 16(%esp),%eax /* arg1 */
movl %eax, -8(%edx)
movl 20(%esp),%eax /* arg2 */
movl %eax, -4(%edx)
xorl %eax, %eax /* %eax <- 0 */
movl %eax, -12(%edx) /* no more caller function */
movl 12(%esp), %eax /* return address */
movl %eax, -16(%edx)
movl 4(%esp), %eax /* context */
movl %edx, 8(%eax) /* %ebp */
subl $16, %edx
movl %edx, 4(%eax) /* %esp */
ret
この関数は、引数 stack が指すメモリ領域をスタック領域に使って動作する、新しいスレッドを作成する。 各レジスタの初期値は引数 context が指す配列に保存される。 このスレッドが最初に実行する関数は、引数 func が指す関数であり、呼出しに際しては、引数 arg1, arg2 が関数引数として渡される。 引数の個数が 2 つであるのは、特別な意味はない。 引数がまったく渡せないと、スレッドの利用者にとって不便であるので、1 つ以上の引数が渡せれることが大切である。
関数 _MakeThread() は、実際には、まず、指定されたスタック領域に、arg2, arg1, 0, func の値を順に積む。 スタックはアドレスの小さい方に向かって伸びるので、オフセットの値は負の値となることに注意してほしい。 このようにすると、このスレッドに切り替わったときに、まず func の値が 関数 _ContextSwitch() からの戻り番地としてスタックから取り出され、func が指す関数の先頭から実行が始まる。 このとき、スタックに積まれているのは上から、関数の戻り番地、第 1 引数 arg1, 第 2 引数 arg2 である。 func が指す関数からの戻り先はないので、関数の戻り番地としては 0 を積んでおけばよい。 最後に、レジスタ ebp と esp の初期値を、引数 context が指す配列に保存する。 それ以外のレジスタの初期値は保存する必要はない。 不定値でよい。
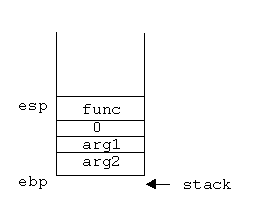
関数 _MakeThread() は、それ自体でスタック領域の確保などをおこなわないので、この関数を呼び出す際には例えば次のようにして、あらかじめスタック領域の確保をおこなう必要がある。
#define STACK_SIZE (4096 * 8) /* 32Kbyte */ char* stack = (char*)malloc(STACK_SIZE); _MakeThread(context, stack + STACK_SIZE, func, arg1, arg2);
スタック領域を malloc() を使って確保し、領域の末尾のアドレスを _MakeThread() に渡す。 malloc() は確保した領域の先頭アドレスを返すので、領域の大きさ分を足してやる必要がある。
作成する関数は主に次の 3 つである。
スレッドが生成されてから、終了するまでの間は、必要に応じてレジスタの値を退避するために int 配列を用意しておかなければならない。 このため、スレッドが生成される度に以下のような構造体 Thread を malloc() で用意し、終了していないスレッドに対応する Thread 構造体をリンクでつなげてリスト構造にしておくこととする。
typedef struct _Thread {
struct _Thread* next;
int thread_id;
int context[CONTEXT_SIZE];
char* stack_top;
int status; /* RUNNING, FINISH, ... */
} Thread;
リンクの先頭は大域変数 threadList が指すものとする。 また現在、実際に実行中のスレッドに対応する Thread 構造体は、大域変数 currentThread が指すものとする。
スレッドを生成する関数 ThreadCreate() は以下のようになる。
typedef void (*ThreadProc)(int);
int ThreadCreate(ThreadProc proc, int arg)
{
static int id = 1;
Thread* child = (Thread*)malloc(sizeof(Thread));
child->thread_id = id++;
child->stack_top = (char*)malloc(STACK_SIZE));
_MakeThread(child->context, child->stack_top + STACK_SIZE,
ThreadStart, (int)proc, arg);
child->status = RUNNING;
/* スレッドを threadList が指すリスト構造に追加する。*/
return child->thread_id;
}
static void ThreadStart(int proc, int arg)
{
ThreadProc ptr = (ThreadProc)proc;
(*ptr)(arg);
ThreadExit();
}
_MakeThread() は第 3 引数として、proc ではなく、ThreadStart() へのポインタを渡す。 これは各スレッドの実行が終了するときに、必ず ThreadExit() が呼ばれるようにするためである。 proc が指す関数の中で明示的に ThreadExit() を呼ぶことにすると、スレッドの利用者の不注意で呼び忘れることがありうるので、proc が指す関数が終了すると暗黙のうちに ThreadExit() が呼ばれるような仕様の方が望ましい。
一方、スレッドの切り替えをおこなう関数 ThreadYield() は次のようである。
void ThreadYield()
{
現在実行中のスレッド currentThread 以外で、
実行可能なスレッド t を探す。
if (t が発見された) {
Thread* cur = currentThread;
currentThread = t;
_ContextSwitch(cur->context, t->context);
}
}
スレッドを終了させる関数 ThreadExit() の仕事は、終了するスレッドに対応する Thread 構造体を threadList が指すリスト構造から取り除き、始めに malloc() で確保したメモリを解放することである。
void ThreadExit()
{
staitc Thread dummy;
Thread* cur = currentThread;
threadList が指すリスト構造から取り除く。
dummy.status = FINISH;
dummy.stack_top = cur->stack_top;
currentThread = &dummy;
free(cur->stack_top);
free(cur);
ThreadYield();
}
最後に ThreadYield() を呼び、残っているスレッドの実行を再開させる。 ThreadYield() は終了してしまったスレッドで使われていたレジスタの値も退避しようとするので、退避先として dummy を指定しておく。 もともとの Thread 構造体は既に free() で解放した後なので、退避先に使うことはできない。
ユーザレベル・スレッドの実装では、一番始めに main() 関数を実行するスレッドだけ特別扱いする必要がある。 OS カーネルから見ると、複数のスレッドが存在することは認識されないので、main() 関数の実行が終了すると、他に終了していないスレッドが存在していても、プログラム全体 (プロセス) が終了してしまう。
これを防ぐためには ThreadYield(), ThreadExit() を工夫して、main() スレッドだけは、他の全てのスレッドが終了するまで、完全には終了しないようにする必要がある。 これまでスレッドの状態 status は最初から最後まで RUNNING で変わらなかったが、main() スレッドの場合に限り、ThreadExit() が呼ばれた後も status を FINISH として残し、他のスレッドが終了した後に終了処理をおこなうことにする。
まず main() 関数の中で main() 用に Thread 構造体を用意するようにする。
void main(int args, char** argv)
{
void ThreadMain(int, char**);
main() 用の Thread 構造体を作成。
currentThread, threadList を初期化。
ThreadMain(args, argv);
ThreadExit();
main() 用の Thread 構造体を解放。
}
関数 ThreadMain() はスレッドの利用者が定義する関数である。 スレッドの利用者は main() の代わりに ThreadMain() を書くことになる。
main() 用の Thread 構造体には、スタック領域を割り当てる必要がない。 main() は OS が最初に割り当てたスタック領域を使って、既に実行中のスレッドである。 そこで stack_top には NULL を代入しておき、後で stack_top の値が NULL か否かで、そのスレッドが main() スレッドか否かを区別できるようにする。
さて ThreadExit() は、main() スレッドを特別扱いしなければならない。
void ThreadExit()
{
static Thread dummy;
Thread* cur = currentThread;
if (cur は main() スレッド)
cur->status = FINISH;
else {
threadList が指すリスト構造から取り除く。
dummy.status = FINISH;
dummy.stack_top = NULL; /* 使用不可 */
currentThread = &dummy;
free(cur->stack_top);
free(cur);
}
ThreadYield();
}
終了しようとしたスレッドが main() スレッドの場合、threadList からそのスレッドを取り除かないので、後に ThreadYield() から戻ってくる可能性があることに注意してほしい。 普通のスレッドの場合は ThreadYield() から戻ってくることはありえない。
この説明では、全てのスレッドが実行を終了した後に、ThreadExit() が main() スレッドの実行を再開して、main() 関数を呼び出し元に return させている。この代わりに、ThreadExit() が直接 exit() を呼ぶようにして もよいだろう。
最後の仕上げは、ThreadYield() を改造して、status が FINISH であるスレッドは、他のスレッドが全て終了するまで実行を再開しないようにすることである。 このようにすれば、main() 関数が呼んだ ThreadExit() は、他の全てのスレッドが終了した後、戻ってくるようになる。
void ThreadYield()
{
現在実行中のスレッド currentThread 以外で、
実行可能 (RUNNING) なスレッド t を探す。
if (t が発見された) {
Thread* cur = currentThread;
currentThread = t;
_ContextSwitch(cur->context, t->context);
}
else if (残りは FINISH 状態の main() スレッドのみ)
main() スレッドの実行を再開する。
return;
}
なお、残り全てのスレッドの実行が終了した後、最後に main() スレッドが ThreadExit() を呼んだ場合、ThreadYield() は _ContextSwitch() を呼んで main() スレッドの実行を再開するのではなく、普通に呼出し元へ戻らなければならない。 この点、ThreadYield() の最後の if 文の条件式には注意が必要である。
並行プログラムは、スレッド切り替えのタイミングによって、プログラムの実行順序が大きく異なってしまう。 このため、プログラムが正しく動作することを机上で検証するのが、逐次プログラムと比べてより面倒である。 各スレッドの実行順序の可能な組み合わせ全てについて、プログラムが正しく動作することを検査しなければならない。
例えば上の ThreadYield(), ThreadExit() の場合では、実行中のスレッドが、
の場合それぞれについて、main() スレッドまたは非 main() スレッドがそれぞれ ThreadYield(), ThreadExit() を呼び出した場合について、プログラムが正しく動くかどうか検査する必要がある。
thread.c を完成させよ。 (このファイルは thread.h を include する。)
完成後、test1.c を使って、ライブラリが正しく動くか確かめよ。 コンパイルするには次のようにすればよい。
% gcc -g -o test1 test1.c thread.c csw-i386.S
また test1.c の ThreadMain() 中で呼ばれている ThreadYield() の位置を動かし、あるいは ThreadYield() を削除して、出力結果から各スレッドがどのような順で動いているのか考察せよ。
これらの関数は次のようにして使う。
#include <stdio.h>
#include <setjmp.h>
void main() {
jmp_buf context;
int result = setjmp(context);
printf("result = %d\n", result);
if (result == 0)
foo(context);
}
void foo(jmp_buf c) {
puts("foo()");
longjmp(c, 2);
}
はじめ setjmp() はレジスタを context に退避し、0 を返す。 longjmp() は、setjmp() で保存されたレジスタを復帰させる。 この結果、longjmp() を実行すると、プログラムの実行は setjmp() が戻るところから再開される。 なお、再開されたときに setjmp() が返す値は、longjmp() の第2引数の値である。
上のプログラムの実行結果は、
result = 0 foo() result = 2
となる。
setjmp()/longjmp() を使った実装のポイントは、各スレッドのスタック領域が重ならないようにすることである。 これを達成するには、スレッドを作成するたびに、大きな空の配列をスタック上に局所変数として割りつければよい。
Copyright (C) 1999-2000 Shigeru Chiba
Email: chiba@is.tsukuba.ac.jp