Web ブラウザと Web サーバは、クライアント・サーバ・モデルに沿った典型的な分散システムである。 この課題では分散システムの作成演習として、web サーバを作成する。 クライアントに相当する web ブラウザは非常に複雑で作成が難しいが、web サーバは比較的作成が容易である。
Web ブラウザと web サーバは、前回説明した TCP/IP プロトコルを使って通信をおこなう。 ブラウザと サーバの間の通信のやり方は HTTP (Hyper Text Transfer Protocol) という規格で定められており、詳細は RFC 1945 という文書に述べられている(注1)。
ブラウザと サーバの間の通信は非常に単純である。 HTML (Hyper Text Markup Language: RFC 1866) を解釈して文章を配置したり、絵を表示したりするのは全て ブラウザの役目で、サーバの仕事はブラウザが求めるファイルを単純に送信することだけである。 サーバはファイルの内容については関知しない。 したがって Web サーバを作るためには、ブラウザから送られてくるファイルの送信要求を解釈し、要求されたファイルをそのブラウザ に送り返すプログラムを書けばよい。 ファイルの送信要求の詳細や、ファイルを送り返す場合のフォーマットなどは HTTP が定めているとおりで、Web サーバを作るのに HTML の詳細を知っている必要はない。
注1:RFC 1945 は HTTP/1.0 の解説であるが、HTTP の最新版は HTTP/1.1 (RFC
2068) である。
この課題では、簡単のため HTTP/1.0 に準拠してサーバを作成する。
もっとも簡単な web サーバは、GET 命令だけを処理できればよい。例えば、そのサーバがマシン host1 で動いており、port 5001 番を listen() しているとしよう。 この web サーバにアクセスするにはブラウザから例えば
http://host1:5001/index.html
を open すればよい。ブラウザはまず、socket を使ってマシン host1 上で port 5001 を listen() しているサーバとの間に connection を張り、
GET /index.html HTTP/1.0\r\n
のような GET 命令を送信する。 末尾の \r\n は改行コードである。 HTTP では DOS 風に CR (\r), LF (\n) の2文字で改行をあらわす。
C 言語や Java 言語では、もともと各文字が内部的に、この文字コードで表現されている (Java 言語の場合、正確には ASCII ではなく Unicode)。 char 型の値の実体は、文字を文字コードに変換して得られる数である。 したがって C 言語の場合、char 型の配列を write 関数に渡すと、そのままハードウェアに渡されて送信される。 Java 言語の場合、char 型は 16 bit の数 (アルファベットの場合、桁数を考えなければ ASCII コードと同じ。上位 bit は 0 になる) なので、8 bit の byte 型に変換しなければならない。
ブラウザは上記の行に続けて、HTTP が定めるいくつかの付加情報を送信するかもしれない。 単純なサーバを作る場合には、最初の1行を受信した後、空行に当たるまでこれらの付加情報を読み飛ばしてよい。 空行は GET 命令の最後を表わす。
GET http://host1:5001/index.html HTTP/1.0\r\n
のような GET 命令を送信する。
GET 命令を受信したら、サーバは要求されたファイルを返送する。 上の例の場合、要求されたファイルは /index.html である。なお、ファイル名は / から始まるが、これは root directory を意味しない。 Web page が置かれている directory を ~/web とすると (これは自由に決めてよい)、実際に返送しなければならないファイルは、~/web を前に付加した ~/web/index.html となる。(注2)
サーバは要求されたファイルをそのままブラウザに送信すればよいが、それに先だって最低限、次のような header 情報を送信しなければならない。(注3)
HTTP/1.0 200 OK\r\n \r\n
\r\n は改行文字である。 最初の行は、GET 命令が正しく受理されて、要求されたファイルを送信することを意味する。 もし何らかの原因で命令を受理できない場合には、HTTP が定める別な header を送信しなければならない。
2行目の空行は header の終了を意味する。 空行につづけて、要求されたファイルの中身をそのまま送信し、全て送信し終わったら、socket を close() すればよい。
非常に簡単ではあるが、とりあえずブラウザを動作させるだけなら、これだけで十分である。
もちろん HTTP に忠実にサーバを作成するなら、さらに header 情報の種類を増やすことができる。
HTTP/1.0 200 OK\r\n Content-length: <送信する html ファイルの長さ (bytes)>\r\n Content-type: text/html\r\n \r\n
新たに追加された2行目は送信するファイルの長さである。 例えば 2000 byte (header の長さを含まない) のファイルを送る場合には、
とする。
一方、3行目はファイルの種別を表す。 HTML ファイルの場合は text/html であり、通常のテキスト・ファイルは text/plain, GIF ファイルの場合は image/gif である。
HTTP の仕様を読むとこの他にも様々な情報を header に付加できることがわかるが、ほとんどの情報は参考情報であり、付加しなくても動作にとくに影響はない。
注2: 実は安全上の理由から、単純に ~/web を先頭に付加するだけではだめである。そうすると、
GET /../../../etc/passwd HTTP/1.0
のような命令で、/etc/passwd のような機密情報のはいったファイルが簡単に取得できてしまうからだ。 ファイル名の中の .. を調べて、不正なファイル・アクセスを禁止しなければならない。
注3: 要求されたファイルが存在するときは
HTTP/1.0 200 OK\r\n \r\n
と送信すればよいが、そのようなファイルが存在しない場合は
HTTP/1.0 404 Not Found\r\n \r\n
とエラーを送信しなければならない。 その場合、header に続いて送るデータがないので、これで送信終了である。
例えば Safari などのブラウザは、URL の先頭に表示するアイコンを 取得しようとして /favicon.ico ファイルを GET 命令で自動的に要求してくる。 そのようなファイルが存在するなら、それを返送すればよいが、そうでない場合は上記のようにステータスコード 404 を送信してエラーを返さなければならない。
以下に web サーバのプログラムの大まかな流れを示す。 本来なら並列処理によって、一度に複数の ブラウザからの要求を受け付けるべきだが、今回は簡単のためブラウザからの要求を逐次的に処理する。
socket()
|
bind()
|
listen()
|
for(;;){ // 無限ループ
accept()
|
GET 命令を read() で受信
|
要求されたファイルの読み込み
|
要求されたファイルを write() で送信
|
close()
}
GET 命令のデータ長は、受け取るファイルの URL の長さによって異なるので、GET 命令の受信には工夫が必要である。
例えばブラウザ側が GET 命令を行末まで、一回の write() によって送信したとしても、サーバ側が送信されたデータ全体を一回の read() によって受信できるとは限らない。 一回目の read() では、例えば半分のデータしか受信できないかもしれないからである。 逆にブラウザ側が複数回の write() によって送信したデータを、サーバ側では一回の read() で受信してしまうかもしれない。
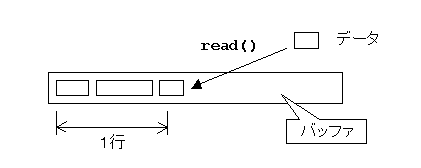
この問題を回避するには、read() で受信したデータは一旦、バッファ領域にため、そこから行末までの一行分、読み出すようにすればよい。 一行読んだ後、バッファ中に余ったデータは、次の行の一部なので、次回まで保存しておく。
これを実行する関数を tcpbuf.h, tcpbuf.c に示す。
これらの関数は次のような役割をもつ。
ファイルの内容を読みこむときも read システムコールを使う (注4)。 しかし read() の第一引数のファイル・ディスクリプタを得るには、socket の場合と異なり、open システムコールを使う。
int fd;
char* filename; /* 読みこむファイルの名前 */
:
fd = open(filename, O_RDONLY, 0666);
:
この間、read(fd, ...) でファイルの先頭から順に読むことができる。
:
close(fd);
もし filename で指定したファイルが存在しないなど、何らかのエラーが発生すると open() は -1 を返す。
この例は読み出し用に open しているが、O_RDONLY の部分を別な定数に変えると、書きこみ用、あるいは読み書き両用に open することも可能である。 詳しくは
% man open
でオンライン・マニュアルを参照のこと。
注4: ファイルの読み書きをするには read(), write() システムコールの他に、mmap() というシステムコールも使える。 大きなファイルを読み書きする場合には、mmap() の方が高速である。
ファイルの大きさは stat システムコールを使えば調べられる。
#include <sys/types.h>
#include <stat.h>
struct stat s;
int size;
char* filename = ... ;
if (stat(filename, &s) != 0)
エラー発生;
else
size = s.st_size;
このように実行すると、名前が filename であるファイルの大きさが size に代入される。
stat() と同様のシステム・コールとして fstat() もある。 これは引数としてファイル名ではなく、ファイル・ディスクリプタをとる。
webserver.c, tcpbuf.c の抜けている部分を埋め、簡単な web サーバを作れ。
コンパイルするには、
とする。 出来上がったサーバを実行するには、
とする。引数はポート番号なので、任意の番号でよい。
この状態でカレントディレクトリに index.html というファイルを作っておくと、そのファイルの中身を web ブラウザから読める。 web ブラウザで
にアクセスしてみよ。 5003 は web サーバのポート番号である。 ホスト名の部分は、web サーバが動いているマシン名、例えば mac701.is.titech.ac.jp に置きかえる。 マシン名はモニタ画面の右上に表示されている。 サーバと web ブラウザが同じマシン上で動いている場合は、localhost とすればよい。 つまり
とする。 index.html の内容が正しく表示されれば成功である。
最後に、サーバを終了させるには ^C を押す。
Web サーバが動作したら、Content-type, Content-length などの付加情報も正しく送信するようにせよ。 Content-type は、要求されたファイルの拡張子 .html などにしたがって決めればよい。 拡張子が .html なら HTML ファイル、.gif なら GIF ファイル、それ以外は plain text である。
Copyright (C) 1999-2000 Shigeru Chiba