無理なリファクタリングはしなくてよい
(以下は CloneTracker のある種の宣伝として書かれた文章です)
無理なリファクタリングはしなくてよい
(株)Sider 千葉 滋
リファクタリングはしなくてもよい、というのは少し極端すぎるタイトルで、 一般論を言えばリファクタリングはした方が良いでしょう。 一方で、リファクタリングは時間がかかるので開発が停滞するとか、 動いているプログラムを動かなくする危険があるとか、負の側面も知られています。
本稿ではリファクタリングをしなくてもよい理由を書くのですが、 リファクタリングには負の側面があるからしなくてよい、 という視点ではなく、リファクタリングをしなくても、いわゆる技術的負債を軽くする方法はある、という視点で書いてみようと思います。 将来、こういう方向の技術が発展するかも、という少し未来予測じみた話です。
最初に背景知識として、リファクタリングの難しさについて書きます。 これは良く知られた話なので、ご存じの方は読み飛ばしてこちらの結論だけどうぞ。
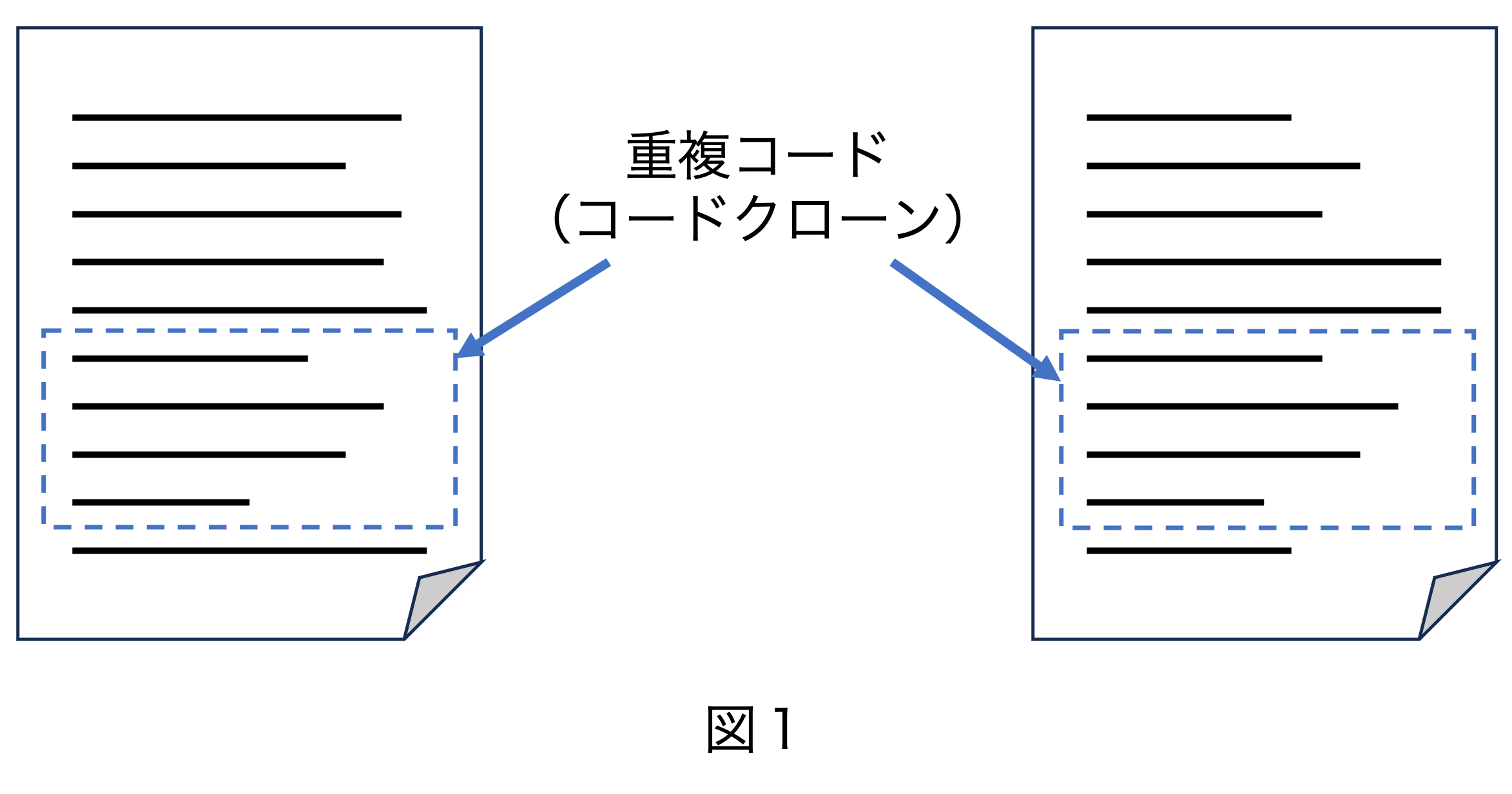
重複コード(コードクローン)
リファクタリングといっても幅広い話です。以下では重複コードを取り除くリファクタリングに絞って話を進めることにします。
重複コードとは、文字通り、プログラムの中に2回以上現れる同じような字面の(しかし完全に同じとは限らない)コード断片のことです。 コードクローンとも言います。 プログラムを書いているときは、似たような処理だからといって、プログラムの一部をコピーして別のところにペーストし、少し直す、という作業をやりがちです。 このような「コピペ」をすると重複コードが知らぬ間に生まれていきます。
重複コードがあると、そこにバグがあった場合、全てのコピーを漏れなく直さなければなりません。 同じようなコードが何カ所にも散らばっているわけです。 一カ所だけバグを修正して、それで直したつもりが、他の場所を直し忘れていて、 いっこうにバグが減らない、ということになりがちです。 こういうことがあるので、重複コードの量はよくコード品質を計る指標にも使われます。
リファクタリングで重複コードをなくす
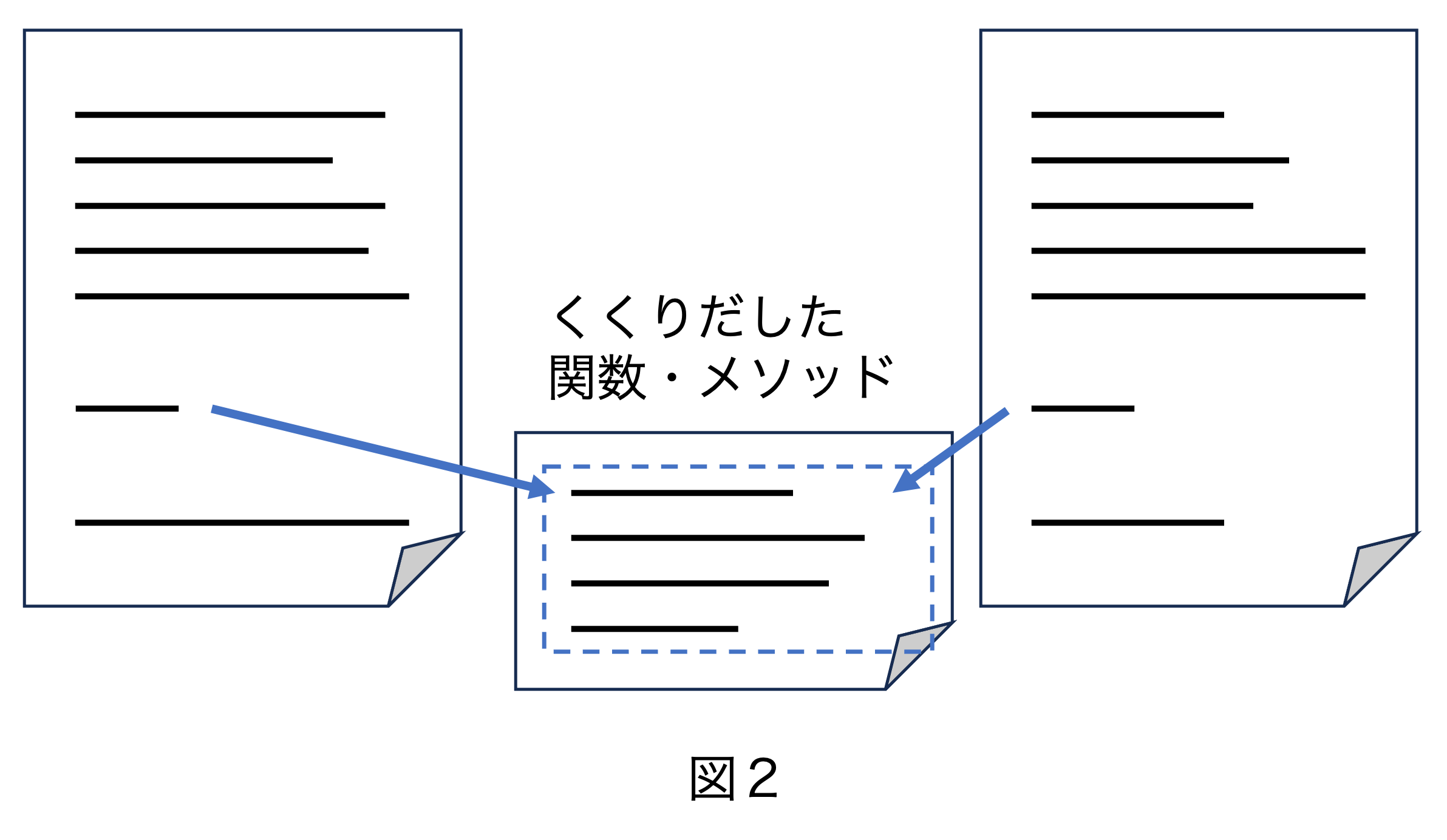
プログラムの中に重複コードがあっても、適切にリファクタリングすれば重複コードを取り除くことができます。 重複部分を関数やメソッドとしてくくりだして、それぞれのコードから呼び出すようにすればよいのです。
例えば図1のようにプログラムの2カ所に重複コードがあるとします。 この部分を図2のように関数やメソッドにくくりだして、それぞれ元の場所から呼び出すようにすれば重複コードを除去することができます。
もっとも重複コードを除去できるといっても、除去後のプログラムが必ず読みやすい良いものになるとは限りません。 重複コードは良くないとはいえ、無理して除去するべきか悩ましいケースも少なくありません。
例えば、 重複コードの前の部分で何か計算をおこなって、 その計算結果を重複コードの中で使っていると、その計算結果をくくりだした関数やメソッドに引数の形で渡さなければなりません。 重複コードの中で計算した結果をその後の部分で利用している場合は、 くくりだした関数やメソッドからそれを戻り値で返さなければなりません。 このようにやり取りする計算結果が増えてくると、 くくりだした関数やメソッドが段々読みにくくなってきます。
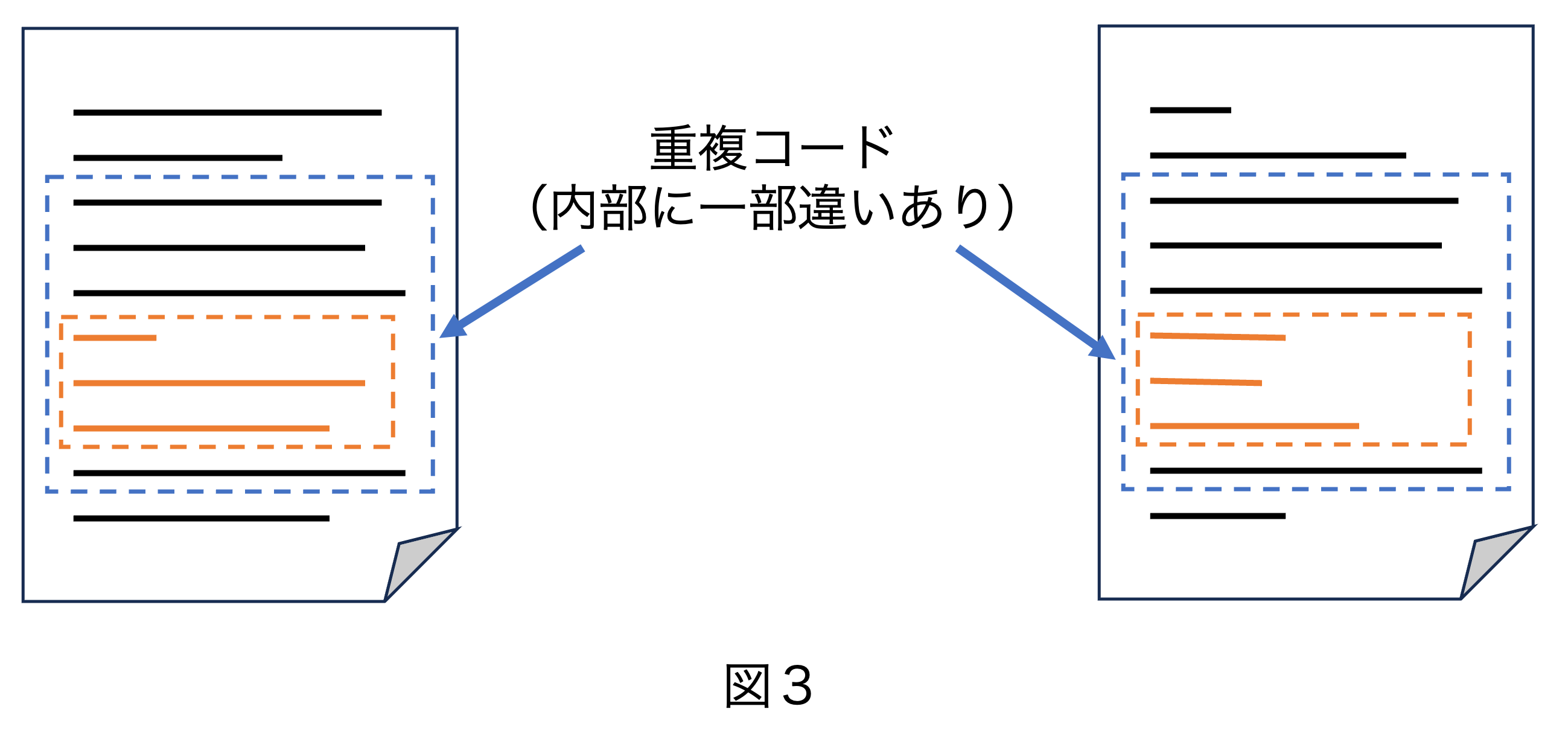
もっと悩ましいケースもあります。 図3はプログラムの2カ所に重複コードがある例ですが、図1と違い、 重複コードが完全に同じではなく、内部に一部異なる(オレンジの)部分があるケースです。 異なる部分があるので、単純に重複コードをくくりだして関数やメソッドにするわけにはいきません。
解決策として例えば図4のように、くくりだした関数やメソッドの中で、 異なる部分を if 文で切り替えて実行しなければなりません。 どちらを選んで実行するかは、関数やメソッドの引数で指定します。 もう少し気の利いた解決策は、重複コード内の異なる部分を関数オブジェクトにする方法です。 くくりだした関数やメソッドにこの関数オブジェクトを引数で渡せば、 完全に同一でない重複コードも関数やメソッドの形でくくりだすことができます。 オブジェクト指向言語なら、関数オブジェクトの代わりにメソッドの上書きを利用してもよいでしょう。
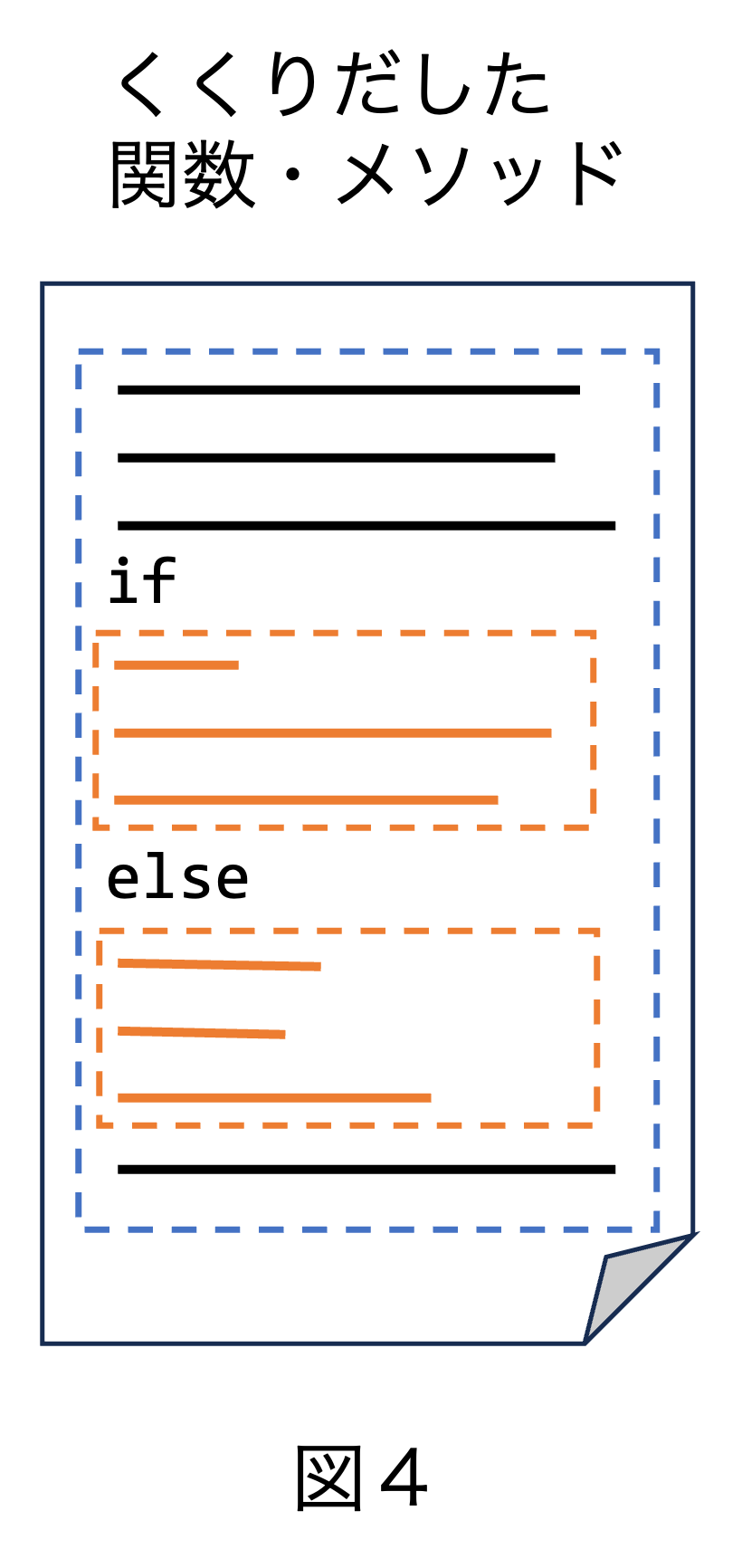
しかしこれらの解決策も完璧とは言えません。 重複コード内の異なる部分が何カ所にも増えてくると、どうやってもリファクタリング後のプログラムが読みやすいとは言い難くなってきます。
重複コードを放置する
一般論を言えば重複コード(コードクローン)はない方がよいわけですが、 リファクタリングによって重複コードを取り除くべきか悩ましいことがあります。
- リファクタリングには時間がかかる。
大規模なプログラムになると、リファクタリングにはかなりの時間がかかります。 リファクタリング後のプログラムが正しく動くか、 リグレッションを起こしていないか、確認する作業も必要です。
- リファクタリングしても技術的に重複コードを上手に取り除けないことがある。
上で述べたように、プログラミング言語の機能の限界により、 確かに重複コードは取り除けるが、 取り除いた後のプログラムが本当に読みやすくなっているか怪しいことがあります。
- 重複コードは時間とともに自然に消えることがある。
重複コードは似たような処理を書こうとして、 既存のコードをコピー&ペーストして(コピペして)少し修正することで生まれます。 プログラムの開発が進むにつれ、元は似たような処理であったはずのコード片が、 どんどん異なる処理をするように書き換えられていき、そのうち重複コードとは呼べなくなる、ということがよくあります。
ずっと重複コードのままなら、少々無理をしてでもリファクタリングして取り除いた方が良いでしょう。しかし、やがて重複コードでなくなるのなら、 そのままにして置いた方が良いでしょう。無理にリファクタリングすると、 かえって良くないかもしれません。 問題は、今、目の前にある重複コードが将来も残るのか、それとも自然に消えるのか、 ちょっと判断がつかないことです。
放置するならどうするか
今すぐ取り除くべきか悩ましい重複コードは、ついついそのままにしてしまいがちです。 しかし、放置された重複コードはしばしば技術的負債として後から開発の重い足かせになります。 どこかで重い腰を上げて無理矢理でもリファクタリングするか、あきらめて技術的負債を払い続けるか、どちらかを選ばなければなりません。
ただ、どちらを選んでも不幸になる二択しか選べないのは、ソフトウェア開発の技術がまだ発展途上だから、と考えることもできます。 重複コードを取り除くためのリファクタリングは人力で作業するわけですが、 そういうリファクタリングは将来、自動化できて欲しいものです(コードのこの部分をメソッドにくくり出せ、のような指示さえ与えれば、今でも自動的にリファクタリングしてくれるのですから)。
もう一つ、重複コードを放置すると技術的負債となって跳ね返ってくるのですが、 それは重複コードの管理が人力だから、とも言えます。 重複コードが技術的負債となるのは、 互いに重複しているコード断片にバグがあったり、機能拡張が必要になって修正するとき、全てのコード断片をもれなく直すべきところ、人手による作業では一部の断片を直し忘れてしまうからです。
どれとどれが互いに重複コードとなっているか自動的に追跡して、修正のときに直し忘れを知らせてくれるツールがあれば、あまり負債を感じなくともすみそうです。 人手で一カ所を直せば他のカ所も同様に自動的に直してくれれば理想です。 今後そういうツールが発展して世に普及してくれば、 無理なリファクタリングならしなくてもよい、という主張もベストプラクティスの一つとして受け入れられるようになるやもしれません。 (株) Sider の CloneTracker もそういう世界を目指したツールの一つです。
重複コードの自動検出は簡単と思う人もいるかもしれませんが、完全に一致する重複コードを探すのならいざ知らず、 よく似ているが一致はしない重複コードを探すのは、さほど簡単ではありません。 またどのくらい似ていたら重複コードと考えるかは難しい問題で、重複コード検出には何十年もの研究の歴史があります。
生産技術としてのプログラミング
コンピュータが生まれてから今日に至るまで、プログラミング言語はずっと進化してきました。 その進化の目的の一つは、ただでさえ行数が長くなりがちなプログラムをできるだけ短く簡潔に書けるようにして、プログラムのどこで何をしているかプログラマが(つまり人が)把握できるようにすることだったと思います。 そのために色々な構文や機能が発明されてきて、それらを駆使すればかなり複雑な処理をするプログラムであっても、 プログラマがきちんと把握できるようになってきました。 そういう構文や機能を使えば、例えば、 あまり似ていない重複コードであっても、一つの関数なりメソッドなりにまとめて重複をなくし、プログラムの見通しを良くできます。
しかしながらこれは「色々な構文や機能を駆使すれば」であって、人手を介在させて上手にリファクタリングすることが前提になっています。 プログラミング言語の色々な構文や機能は、あくまで人が使う道具であって、 使う人のスキルによって道具としての性能が左右されます。 だからこそ使いこなせるようにスキルを磨く楽しみが人間の方にはあるのですが、 生産技術としてみると手工業なので現代的とはあまり言えないかもしれません。
手工業の先には機械工業があるとすると、プログラミングにもそういう時代が来るかもしれません。 重複コードがあっても無理してリファクタリングせず、人手を介さずに自動的に重複コードの存在を追跡してすませる、というやり方を上に書きました。 もしかすると、こういうやり方の方が生産技術としては先進的なのかもしれません。 職人的なプログラマとしては少し受け入れがたい話ではありますが。